Approach Overview
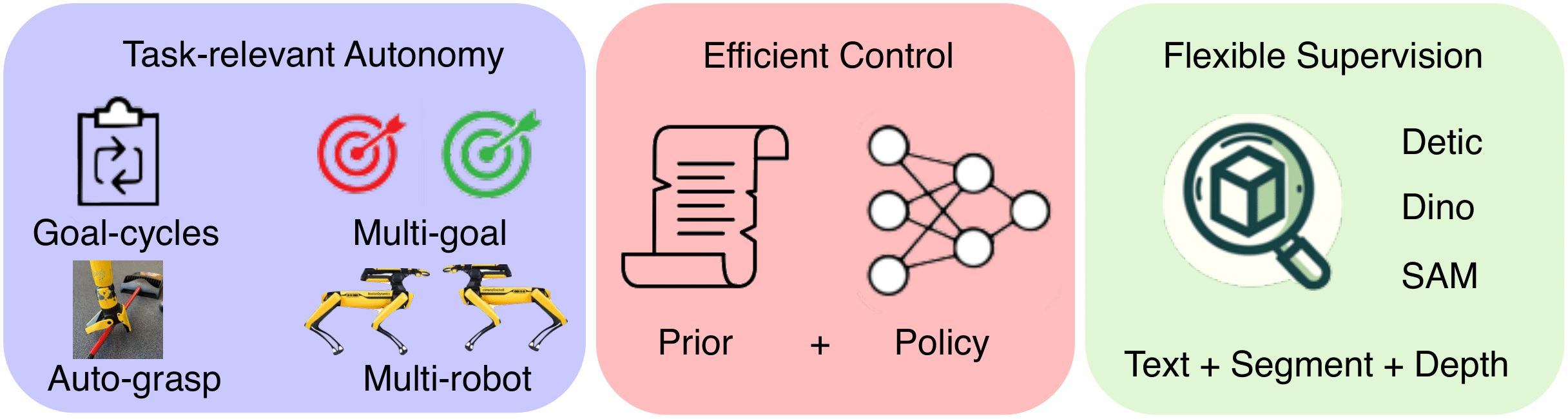
Task-relevant Autonomy: Ensures data collected is likely to have learning signal
Efficient Control: Use signal to learn skills and collect better data
Flexible Supervision: How to define learning signal for tasks
We show the evolution of the robot's behavior as it practices and learns skills.
These are learned over 8-10 hours practice in the real world.
Task-relevant Autonomy: Ensures data collected is likely to have learning signal
Efficient Control: Use signal to learn skills and collect better data
Flexible Supervision: How to define learning signal for tasks
The full action space for the robot (left) is very large, and it rarely interacts with objects.
Our approach leads the robot to grasp objects (right), leading to data with better signal.
Note that the robot isn't yet performing the task of standing up the dustpan.
Goal cycles ensure the robot can keep learning without stagnation.
Leveraging priors helps collect data with better learning signal.

Planners (rrt*) with simplified models,
for navigation (chair)

Movement restriction based on
distance to detected object (sweeping)
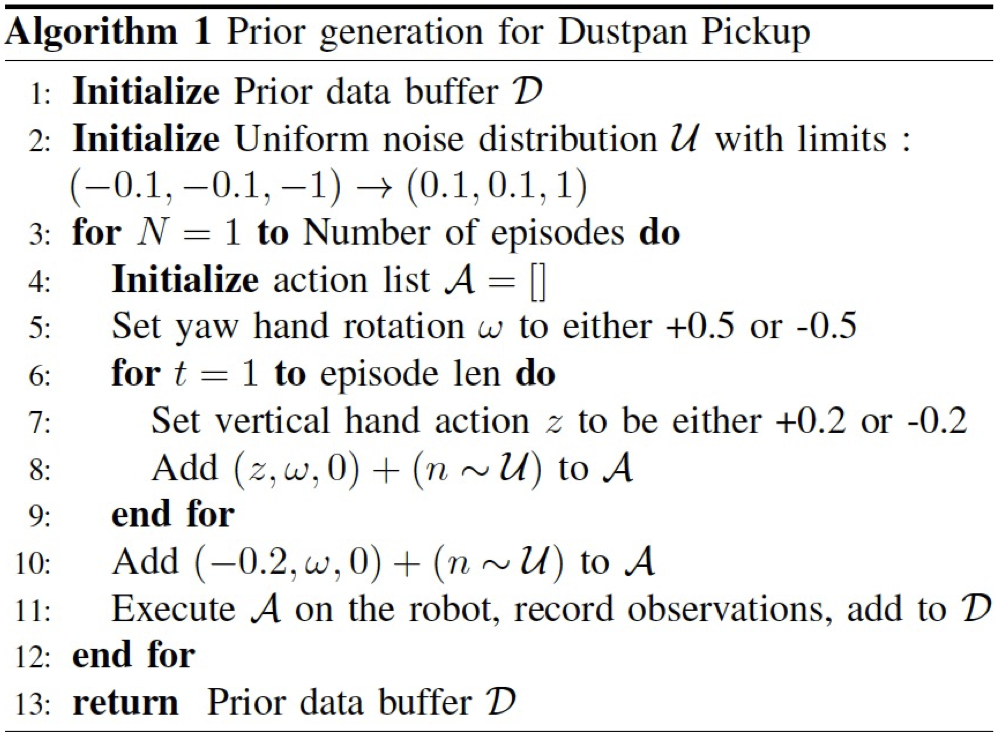
Simple scripted behavior (dustpan standup)
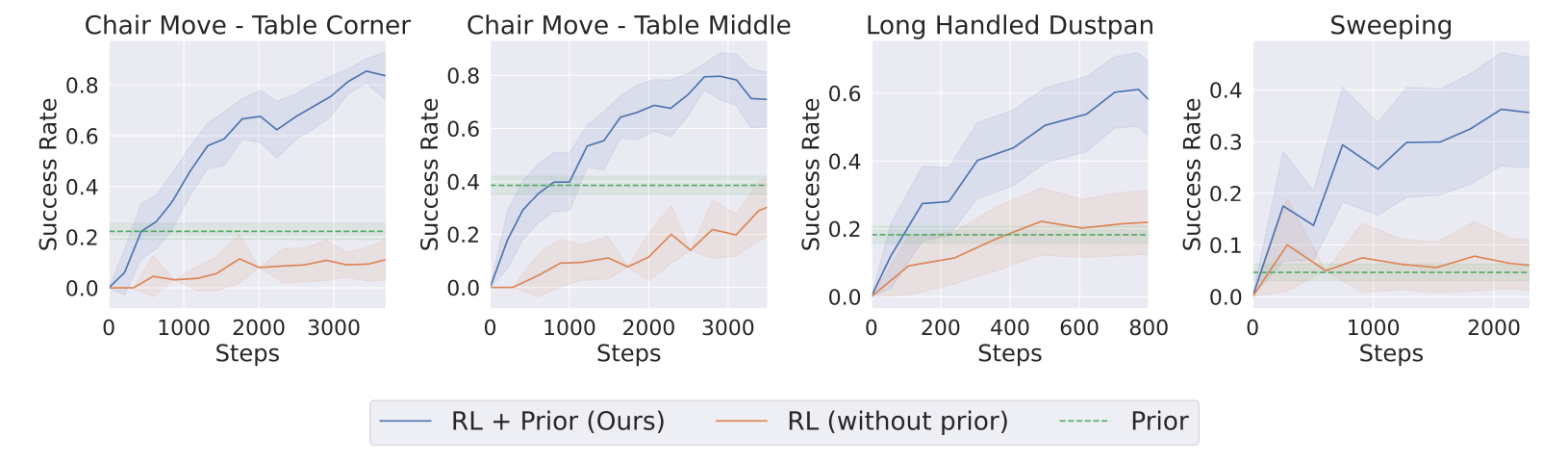
We combine RL with behavior priors to learn with very few samples.
Priors while useful are not sufficient to reliably perform the task. RL without priors is very inefficient.
Note all compared approaches shown use task-relevant autonomy.
Text prompts used to get object masks from Segment Anything for chair moving(left) and sweeping (right).
These are combined with depth observations to obtain state estimates, used to define reward.


With higher policy entropy, RL sometimes discovers new behaviors that complete the task, quite different from the prior.
@inproceedings{mendonca2024continuously,
title={Continuously Improving Mobile Manipulation with Autonomous Real-World RL},
author={Mendonca, Russell and Panov, Emmanuel and Bucher, Bernadette and Wang, Jiuguang and Pathak, Deepak},
journal={Conference on Robot Learning},
year={2024}
}